
 |
| AI-generated image from www.freepik.com |
1. From Data to Decisions
Aritificial Interlligence (AI)
เรามาเริ่มจากคำถามง่ายๆ ว่า ปัญญาประดิษฐ์ (AI) คืออะไร? หนึ่งในคำตอบ อาจจะเป็น ความสามารถของคอมพิวเตอร์ที่เลียนแบบมนุษย์ในด้านต่างๆ เช่น เรียนรู้ แก้ปัญหา และตัดสินใจได้อย่างอย่างมีเหตุผล (rational) [1] ความสามารถในการใช้เหตุผลนี่เองที่ทำให้สิ่งนั้นเรียกได้ว่า มีสติปัญญา (Intelligence)
 |
| AI: The Agent and the Environment [2] |
Machine Learning (ML)
Machine Learning สายย่อยของ AI ซึ่งพัฒนาให้คอมพิวเตอร์สามารถเรียนรู้ โครงสร้าง และรูปแบบของข้อมูล สามารถนำความรู้นั้นมาใช้กับข้อมูลชุดใหม่ๆได้ [1] หรืออาจกล่าวได้ว่า Machine Learning เป็นกระบวนการเรียนรู้จากข้อมูล โดยการเลือกใช้อัลกอริธึมที่เหมาะสมกับข้อมูลนั้นๆ ซึ่งผลลัพธ์ที่ได้ ช่วยให้ AI สามารถ ใช้เหตุผล หรือตัดสินใจได้ โดยผ่านกลไกของ Machine Learning นั่นเอง
 |
| ML: The Learning Machine |
เห็นได้ว่าปัจจัยที่สำคัญ คือ ข้อมูล และ อัลกอริธึม ในส่วนของข้อมูลนั้น มีได้หลายรูปแบบ ทั้งข้อมูลที่เราคุ้นเคยเป็นตาราง ภาพถ่าย วิดีโอ ไฟล์เสียง หรือแม้แต่สัญญานไฟฟ้าจากเซ็นเซอร์ต่างๆ ส่วนอัลกอริธึมนั้น ในบริบทของ ML จะหมายถึง สูตรหรือลำดับขั้นตอนทางคณิตศาสตร์ ซึ่งใช้เพื่อถอดรูปแบบจากข้อมูล ตัวอย่างเช่น Linear Regression, Decision Trees, k-Nearest Neighbors (k-NN) หรือ Neural Networks
ดังนั้นที่มาของเหตุผลของ AI จึงเกิดจากการประมวลผลทางคณิตศาสตร์ร่วมกับตรรกะ เช่น ความน่าจะเป็น (Probability), Linear Algebra, Optimization, Maximize Reward หรือ Minimize Penalty รวมไปถึงกฏเกณฑ์ต่างๆ (Rule-Based) ลำพังการประมวลผลกลุ่มนี้ต้องใช้ทรัพยากรเครื่องคอมพิวเตอร์สูง (Computationally Intensive) และเมื่อต้องคำนวณร่วมกับข้อมูลมหาศาลแล้ว ทำให้การประมวลผลกลายเป็นงานยากเข้าไปอีก จึงเป็นเหตุผลที่ AI เริ่มเข้าสู่ยุคบูมในช่วงเริ่มมี Cloud Computing แล้ว
ความสัมพันธ์ระหว่าง Artificial Intelligence และ Machine Learning
เราอาจมองได้ว่า AI เป็นเทคโนโลยีที่ทำให้คอมพิวเตอร์ฉลาดและสามารถทำงานที่ซับซ้อนเหมือนมนุษย์ได้ ส่วน ML นั้นเน้นเรื่องการเรียนรู้ของคอมพิวเตอร์จากข้อมูล ดังนั้นในแง่ความสัมพันธ์ระหว่าง AI และ ML เราอาจเปรียบเทียบได้ว่าถ้า AI เปรียบเสมือนรถยนต์ ML เป็นเสมือนเครื่องยนต์ที่ขับเคลื่อน AI และเราสามารถเลือกใช้เครื่องยนต์ให้เหมาะสมกับรถยนต์ หรือแม้แต่ปรับตามความก้าวหน้าของเทคโนโลยีในอนาคต เหมือนกับเที่เราเปลี่ยนจากเครื่องยนต์สันดาบภายในไปเป็นมอเตอร์ไฟฟ้านั่นเอง
เรามักพบเห็นการใช้คำเรียก AI ในบริบทของ Machine Learning หรือสลับกัน โดยเฉพาะในแง่การตลาด เพื่อให้ฟังดูทันสมัย ขายไอเดียได้ง่าย จนผู้คนในชุมชน AI เองก็คร้านจะเอามาเป็นประเด็น แต่ในฐานะคนในสายเทคโนโลยี ก็ควรรู้ไว้ว่า มันเป็น 2 เรื่องที่แตกต่างกัน
 |
| ความสัมพันธ์ระหว่าง AI กับ ML |
พฤติกรรมของ Artificial Intelligence
ตอนนี้เรารู้แล้วว่าเบื้องหลังความฉลาดและมีเหตุผลของ AI เกิดจาก Machine Learning ดังนั้นเรามาทำความเข้าใจว่า ที่มีข่าวว่า พบปัญหา AI แสดงความก้าวร้าว ความลำเอียง เลือกปฎิบัติ (bias) หรือแม้แต่จะมาครองโลกแทนมนุษย์ (เออ... อาจจะดีก็ได้นะ) ซึ่งประเด็นเหล่านี้ ล้วนเป็นความเสี่ยงจากการใช้งาน AI โดยส่งผลกระทบถึงองค์กรที่นำ AI มาใช้ ไม่ว่าจะเป็น ความไม่ยุติธรรม ความผิดพลาด ชีวิตและทรัพทย์สิน การฟ้องร้อง ไปจนถึง ความสงบสุขของพวกเราชาวโลกเลยทีเดียว
มีการเปรียบเทียบที่น่าสนใจ[3] ว่า พฤติกรรมของ AI นั้น เทียบเคียงได้กับพฤติกรรมของมนุษย์ ซึ่งเกิดจาก พันธุกรรมที่ได้จากพ่อและแม่ (nature) และการอบรมเลี้ยงดู (nurture) ซึ่งจากผลการศึกษา เรารู้ว่าการอบรมเลี้ยงดูหรือสิ่งแวดล้อม มีผลอย่างมากต่อพฤติกรรมของคนเรา เด็กที่เกิดจากพ่อแม่ที่ดูเป็นคนดี แต่ถ้าได้รับการเลี้ยงดูที่ไม่ดี หรืออยู่ในสังคมที่ไม่ดี ก็อาจจะโตไปเป็นคนไม่ดีได้ (เหมือนเอี้ยคังกับเอี้ยก้วย แหละ) AI ก็เช่นกัน พฤติกรรมเกิดจาก เลือกใช้อัลกอริธึมและตรรกะ ซึ่งเปรียบเสมือนพันธุกรรม (nature) และข้อมูลจำนวนมากที่ให้ AI ใช้เพื่อเรียนรู้ ซึ่งเปรียบเสมือนการอบรมเลี้ยงดู (nurture) จากมุมแบบเชิงเปรียบเทียบแบบนี้ ทำให้เราเห็นภาพได้ว่า การเลือกใช้ข้อมูลที่ดีและเหมาะสมนั้นมีส่วนสำคัญอย่างมากต่อ AI การที่ AI มี ก้าวร้าว ลำเอียง เลือกปฏิบัติ หรือให้ผลลัพธ์ที่ผิดพลาด ล้วนมีสาเหตุมาจากข้อมูลที่เลือกให้ AI ใช้เรียนรู้ ดังนั้นถ้า AI คิดจะครองโลก ก็คงเพราะพวกเรานั่นแหละ
 |
| AI Behavior vs Human Behavior |
2. Learning Paradigm
ถึงตอนนี้เรารู้แล้วว่าข้อมูลที่ใช้เพื่อให้ Machine Learning ได้เรียนรู้มีผลต่อการทำงานของ AI อย่างมาก ดังนั้น เพื่อให้เราเข้าใจถึงผลกระทบของข้อมูลต่อ AI เราไปเยี่ยมเยือนห้องเรียนของ AI กัน รูปแบบการเรียนรู้ของ Machine Learning นั้นแบ่งออกมาหลักๆ ได้ 3 รูปแบบ ซึ่งแต่ละแบบมีจุดที่แตกต่างกัน
1. Supervised Learning การเรียนรู้จากข้อมูลที่ระบุผลลัพธ์ (label)ไว้ล่วงหน้า วิธีการนี้คือการที่ ML พยายามสร้างความสัมพันธ์ทางคณิตศาสตร์ระหว่างข้อมูลกับผลลัพธ์ ที่ระบุไว้ ตัวอย่างเช่น เราต้องการสอนให้คุณหมอ AI จำแนกระหว่างภาพเอกซเรย์ปอดที่สุขภาพสมบูรณ์ กับปอดที่มีอาการอักเสบติดเชื้อ เราต้องเตรียมภาพเอกซเรย์ปอดทั้ง 2 แบบ โดยระบุผลตรวจจากคุณหมอผู้เชี่ยวชาญในทุกๆ ภาพ เพื่อให้คุณหมอ AI ได้เรียนรู้ และสามารถวินิจฉัยภาพเอกซเรย์ภาพใหม่ได้ โดยไม่ใช่การจดจำ
 |
| Supervised Learning |
หากมองในแง่ข้อมูล Supervised Learning ต้องมีการเตรียมข้อมูล ที่ระบุผลลัพธ์ (label) ที่ถูกต้องแม่นยำ ดังนั้นในขั้นตอนการเตรียม ต้องใช้ข้อมูลที่น่าเชื่อถือ มีความถูกต้อง และปราศจากความลำเอียง (bias) ในข้อมูล ซึ่งอาจจำเป็นต้องใช้ผู้เชี่ยวชาญ ในขั้นตอนการเตรียมข้อมูล เช่น จากตัวอย่างคุณหมอ AI ข้างต้น ผลวินิจฉัยจากภาพเอกซเรย์ต้องมีความถูกต้อง ภาพมีรายละเอียดชัดเจน มีกลุ่มตัวอย่างที่เพียงพอ เป็นต้น
ตัวอย่างการใช้งานจากการเรียนรู้ในกลุ่มนี้ได้แก่ disease diagnostis, personalized treatment plan, credit scoring and risk assessment, loan default prediction
2. Unsupervised Learning การเรียนรู้โดยการหารูปแบบและความสัมพันธ์ระหว่างข้อมูล โดยข้อมูลไม่ต้องมีการระบุผลลัพธ์ ตัวอย่างเช่น เราต้องการให้คุณหมอ AI ช่วยจำแนกประเภทของภาพเอกซเรย์ปอด โดยที่เราไม่มีผลลัพธ์ว่าแต่ละภาพมีผลวินิจฉัยเป็นอย่างไร Machine Learning จะสามารถแบ่งภาพออกมาเป็นกลุ่มๆ จากการวิเคราะห์ แต่คุณหมอ AI จะยังไม่รู้หรอกนะ ว่าแต่ละกลุ่มมีความหมายอย่างไร ตรงนี้ต้องมีคุณหมอที่เป็นผู้เชี่ยวชาญมาช่วยวิเคราะห์ตีความภาพแต่ละกลุ่มในภายหลัง (label) เช่น กลุ่มที่ 1 คือ ปอดสุขภาพดี กลุ่มที่ 2 คือปอดที่มีอาการอักเสบติดเชื้อ กลุ่มที่ 3 คือกลุ่มที่มีเนื้องอก หรือแต่ละกลุ่มอาจเป็นระยะของการเกิดโรค เป็นต้น
 |
| Unsupervised Learning |
หากมองในแง่ข้อมูล Unsupervised Learning ซึ่งต้องเรียนรู้จากรูปแบบ และลักษณะโครงสร้างของข้อมูล จึงต้องมีคุณภาพสูงเพียงพอ ข้อมูลถูกต้อง ชัดเจน เช่นจากตัวอย่างคุณหมอ AI ข้อมูลภาพเอกซเรย์ต้องมีรายละเอียดที่ชัดเจนเพียงพอ เป็นต้น
ตัวอย่างการใช้งานจากการเรียนรู้ในกลุ่มนี้ได้แก่ analyzing CT scans, genetic clustering, anomaly detection, fraud detection
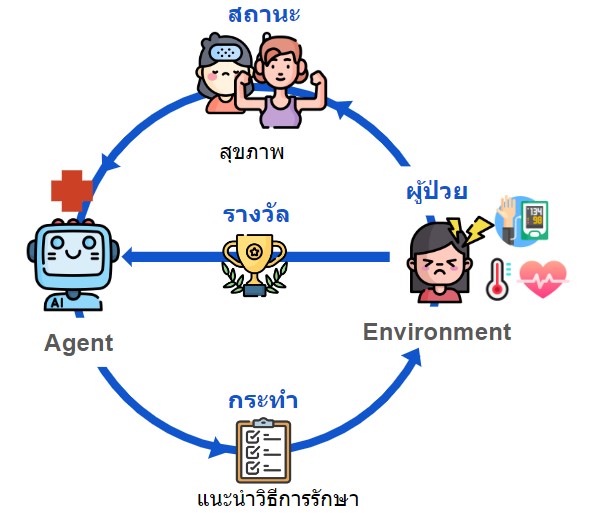
3. Reinforcement Learning การเรียนรู้ในแบบที่ 3 แตกต่างจาก 2 แบบแรก ตรงที่ใช้หลักการมีปฏิสัมพันธ์ระหว่าง Agent กับ Environment และกลไกการให้รางวัล (ให้คะแนน) หรือลงโทษ (หักคะแนน) จากสถานะ (ผลลัพธ์) ที่เกิดขึ้นจาก Action ที่ Agent สร้างขึ้น ตัวอย่างเช่น คุณหมอ AI ให้คำแนะนำ (Action) ในการรักษาผู้ป่วยที่มีอาการไข้สูง โดยคุณหมอมนุษย์ที่เป็นผู้เชี่ยวชาญทำการประเมินข้อแนะนำ และนำไปรักษาคนไข้ หากคนไข้อาการดีขึ้น ก็จะให้คะแนนกับคุณหมอ AI แต่หากว่าอาการไม่ดีขึ้นหรือแย่ลง ก็หักคะแนน ซึ่งคุณหมอ AI มีอัลกอริธึมที่เลือกแนวทางรักษาที่ได้คะแนนสูงสุด โดยวิธีนี้ คุณหมอ AI ก็จะค่อยๆ เรียนรู้ว่า ถ้าคนไข้มีอาการไข้สูง ต้องให้การรักษาแบบไหน ถึงจะได้ผลดี
 |
| Reinforcement Learning |
หากมองในแง่ข้อมูล Reinforcement Learning ซึ่งเป็นการเรียนรู้จากปฏิสัมพันธ์ระหว่าง AI กับสิ่งแวดล้อม ดังนั้นข้อมูลที่มีคุณภาพ จึงหมายถึง ความถูกต้องของ สถานะ การกระทำและรางวัล/คะแนน (state-action-reward) การให้รางวัล หรือลงโทษจากผลของการกระทำ ที่สอดคล้อง ตรงไปตรงมา ซึ่งในจุดนี้ก็ไม่ต่างจากการเรียนรู้ของสิ่งมีชีวิตอื่นๆ รวมถึงมนุษย์มากนัก
ตัวอย่างการใช้งานจากการเรียนรู้ในกลุ่มนี้ได้แก่ patience treatment recommendation, personalized recommendation, automated stock trading
การเรียนรู้ทั้ง 3 รูปแบบถือเป็นรูปแบบพื้นฐานในการเรียนรู้ของ Machine Learning และสามารถนำมาใช้ร่วมกันได้ ตัวอย่างเช่น ChatGPT (หรือ GPT model) ของ OpenAI ที่เริ่มต้นจากการเรียนรู้แบบ Unsupervised Learning โดยใช้เนื้อหาบทความจากแหล่งต่างๆ ใน internet ให้ AI เรียนรู้ รูปแบบของการใช้คำ การเรียงรูปประโยค การเชื่อมประโยค แล้วทำการปรับแต่งด้วย Supervised Learning เพื่อ โดยการเตรียมชุดข้อมูล เพื่อให้สามารถเลือกใช้คำและรูปประโยคได้อย่างเหมาะสม ตรงนี้เหมือนสอนหลักไวยกรณ์และมารยาททางภาษาให้กับ AI และในขั้นตอนสุดท้าย จึงใช้ Reinforcement Learning ให้ผู้ทดลองใช้งานให้คะแนนการตอบข้อความของ ChatGPT เพื่อปรับปรุงคุณภาพของผลลัพธ์ที่ได้
3. Taming the AI Beast: Preventing AI Misbehavior
ข้อมูลเป็นหัวใจสำคัญของการพัฒนา AI เราอาจจะเคยได้ยินว่าข้อมูลยิ่งมาก ยิ่งดี แต่ในความเป็นจริงแล้ว ข้อมูลมีอายุขัย (Shelf life) เช่นกัน นอกจากนั้น ข้อมูลที่ไม่มีคุณภาพ เลือกมาไม่ดีกลับส่งเสียผลมากกว่า ในที่นี่เรายังไม่พูดถึงธรรมาภิบาล AI (AI Governance) แต่เรามาทำความรู้จักอคติหรือ bias ในข้อมูลและผลกระทบกับ AI กัน คนที่มีความรู้ด้านสถิติ จะเข้าใจว่าผลของ bias ในข้อมูล ทำให้ผลวิเคราะห์มีความผิดเพี้ยน ลดทอนความน่าเชื่อถือของผลวิเคราะห์ แต่ในกรณี AI ซึ่งมีปฏิสัมพันธ์กับมนุษย์ มันมีผลกระทบในวงกว้างกว่านั้น และอาจมีผลถึงชีวิตผู้คนเลยทีเดียว
Data Bias หรือความลำเอียงในข้อมูล เป็นความบกพร่องหรืออคติที่ปรากฏอยู่ในข้อมูล เกิดขึ้นได้จากหลายสาเหตุ แต่ในกรณีของ AI มักเกิดขึ้นโดยไม่ตั้งใจ เช่น ใช้กลุ่มข้อมูลไม่หลากหลายพอ อาจมีข้อมูลจากลุ่มประชากรบางกลุ่มที่มากหรือน้อยเกินไป หรือวิธีการจัดหาข้อมูลที่บกพร่อง สำหรับเทคโนโลยี AI ในปัจจุบัน ต้องใช้การเรียนรู้กับข้อมูลจำนวนมาก ทำให้เราอาจละเลย หรือแม้แต่ไม่รู้เลยว่าข้อมูลนั้นมี bias อยู่ ข้อมูลอคตินั้นมีได้ตั้งแต่เรื่องของ สถานะทางสังคม เชื้อชาติ ศาสนา เพศ การศึกษา หรือเรื่องอื่นๆ

References:
[1] https://professionalprograms.mit.edu/blog/technology/machine-learning-vs-artificial-intelligence/
[2] http://www.ai.mit.edu/courses/6.825/fall02/pdf/6.825-lecture-01.pdf
[3] Wharton Online's AI Strategy and Governance by the University of Pennsylvania
[4] https://www.prolific.com/resources/shocking-ai-bias
[5] https://www.wired.com/story/bias-statistics-artificial-intelligence-healthcare/
[6] https://www.bbc.com/news/articles/c9xx8122893o
 Reviewed by aphidet
on
8:35 AM
Rating:
Reviewed by aphidet
on
8:35 AM
Rating:





No comments: